Table of Contents
hide
FILE MANAGEMENT
Introduction
- Typically, files in a file system are organized and associated with several file attributes, including the file name, size, creation and modification timestamps, permissions, and file type. These attributes provide detailed information about the file and determine how it can be accessed and manipulated.
- In file management, directories (also known as folders) are used to organize/store, and group related files. They create a hierarchical structure that helps users and applications navigate and locate files. Directories can contain both files and subdirectories, allowing for a structured organization of data. They allow users to group related files together and create a logical structure. Directories can be nested within other directories, forming a tree-like structure.
- Understanding file attributes is essential for efficient file system management and operating system design, ensuring security, access control, and optimized use of storage.
Definition
- In an Operating System (OS), a file is a collection of related information stored on secondary storage, such as a hard disk, SSD, or flash drive.
- File management in an operating system (OS) refers to the processes and tools used to organize, store, manipulate, control, and retrieve files and directories on a computer. It involves tasks such as creating, deleting, copying, moving, and searching for files, as well as managing file permissions and access control.
File Attributes
- File attributes are metadata associated with files that help the OS and users manage, access, and secure files properly.
- File attributes help manage files on secondary storage systems, such as:
- Hard Disk Drives (HDD)
- Solid State Drives (SSD)
- Optical disks
- USB drives
- The OS uses file attributes to:
- Keep track of file locations and sizes.
- Perform access control depending on user and permission attributes.
- Index and search files efficiently.
- Maintain data integrity and backup systems.
- Each file stored in a filesystem has a set of attributes that describe its properties. These are –
- Name
- It is the human-readable identifier for the file.
-
It is used in the Identification of the file
- For example: document1.txt, image1.jpg.
- This attribute is used to access or manage the file.
-
Identifier
-
It is a unique tag or number (usually an index or inode) used internally by the OS to identify the file.
-
It supports internal tracking, not visible to users.
-
-
Type
-
This attribute indicates the nature or format of file contents.
-
It recognizes the format or usage of the file.
-
For example: .txt, .pdf, .jpg, .exe, etc.
-
This attribute helps the OS or user applications open files with the suitable program.
-
- Location
- Name
-
-
- It gives the physical position of the device.
- It is the address or path where the file data is stored on secondary storage.
- Filesystems of an operating system manage locations using block addresses or pointers in inodes.
- Size
-
-
-
- It is the storage space used.
- It is the current size of the file in bytes or kilobytes.
- It helps in storage allocation and file transfers.
-
-
-
- Protection (Permissions)
- This is the security setting or Access control for users that defines who can read, write, or execute the file during operations or activities.
- This protection can be applied to different types of users: Owner, Group, and Others, and in different modes: Read (r), Write (w), Execute (x).
- For example (Linux): rwxr–r– (Owner can read/write/execute; others can read only).
- Flags
- This is the special indicator that enables or restricts file operations, hence called behaviour indicators.
- This attribute is used to display the activity’s status.
- For example:-
-
– Archive (used for backups)
– Hidden (excluded from display in normal view)
– Read-only
– System file
-
- Timestamps (Time and Date Information)
- This attribute includes –
- Creation Time – when the file was first created.
- Last Modification Time – the last time the content was changed.
- Last Access Time – the last time the file was read.
-
This Info tracks modification/access history.
- This attribute is essential for version control, backups, and file synchronization.
- This attribute includes –
- 9. Owner and Group
-
This attribute enables multi-user management and security.
- This attribute helps in implementing file security and user access control, and includes –
- Owner: The user who created or owns the file.
- Group: A collection of users with shared access rights.
-
- Timestamps (Time and Date Information)
File Types
- In an operating system, file types refer to the different kinds or formats of files stored on a computer or any secondary storage device like a hard drive or USB.
- Each file type has a specific structure and is used for a particular purpose, like storing text, images, audio, or programs.
- File types are usually identified by their file extensions, such as
.txt,.jpg,.mp3, or.pdf. These extensions help both the user and the system know which application should open the file and how to handle it. - File types help both the operating system and users manage files effectively, especially on secondary storage.
- Understanding file types is important because it helps organize data, select the right software to open files, and manage storage effectively. On secondary storage, file types also help the operating system read and write data properly.
- For example:
- A
.txtfile is a simple text file that can be opened with Notepad. - A
.jpgfile is used for images and can be opened with a photo viewer. - A
.mp3file stores audio and is played using a music player.
- A
-
On secondary storage devices like HDDs, SSDs, and USBs:
- Files are stored with metadata that includes the file type.
- File types affect how data is written, stored, and retrieved.
- OS and applications use file extensions to determine how to handle a file.
-
File types help users to identify content and open it with the appropriate tools.
-
Using this, the OS knows whether the file is executable or needs an interpreter.
-
By knowing file types, systems can warn about potentially harmful types like .exe.
-
By knowing file types, file extensions help in categorizing during searches.
-
Classification of File Types
We can group file types into categories, which are as follows:
-
- Text Files
- This file stores characters in readable formats like ASCII or Unicode.
- For example: – .txt (Plain text), .csv (Comma-separated values), .log (Log files).
- This file is used in Notes creation, configuration, program outputs, plain text writing, logs, etc.
- Document Files
- This file is used in file creation by word processors or other editing software.
- For example: .doc, .docx (Microsoft Word), .pdf (Portable Document Format), .odt (OpenDocument Text), etc.
- This file is used in making reports, resumes, eBooks, formal documents, etc.
- Spreadsheet Files
- This file contains tables, numbers, formulas, etc.
- for example: .xls, .xlsx (Microsoft Excel), .ods (OpenDocument Spreadsheet) ,etc.
- This file is used in financial data, grade books, and inventories
- Presentation Files
- This file is used to create and display slides.
- For example: .ppt, .pptx (PowerPoint), .odp (OpenDocument Presentation), etc.
- This file is used in educational or business presentations
- Image Files
- This file is used to contain visual data that can be viewed using image viewers.
- For example: .jpg, .jpeg, .png, .gif,.bmp (bitmap image), etc.
- This file is used in photography, web photos, screenshots, etc.
- Audio Files
- This file is used to store sound information in a format that users can play.
- For example: .mp3 (compressed audio), .wav (high-quality audio), .m4a, .aac, etc.
- This file is used in the creation of Music, voice recordings, podcasts, etc.
- Video Files
- This file is used to store moving visuals and possibly audio.
- For example: .mp4, .mkv, .avi, .mov, etc.
- This file is used in the making of Movies, video tutorials, recorded events, etc.
- Web Files
- This file is used in web design or development.
- For example: .html (HyperText Markup Language), .css (Cascading Style Sheets), .js (JavaScript), etc.
- This file is used in making websites, web apps, etc.
- Programming Files
- This file is used to create source code written in various programming languages.
- For example: .c, .cpp, .java, .py, .js, .html, etc.
- This file is used in Application development, scripting, etc.
- Text Files
File Access Methods
- File access methods are the techniques or ways used by an operating system to read from and write to files stored on secondary storage.
- These methods determine how data is accessed within a file (sequentially, directly, or some other way).
- Access methods are essential because files may be organized differently depending on their use (text, random records, multimedia, etc.), and efficient access is necessary for performance.
- The selection of a file access method depends on:-
- The type of application
- The structure of the data
- The performance requirements
- A good understanding of access methods helps developers and OS designers manage data more efficiently in storage systems.
- Operating systems mainly support three types of file access methods:-
- Sequential Access
- In this way, data is accessed in a linear order, from the beginning of the file to the end.
- In this, we cannot skip any data and go through all previous data to reach a particular point.
- Mostly applied for simple text documents, log files, batch processing, etc.
- For example, A music playlist where songs play one after another.
- It performs operations –
read_nextorwrite_next - Advantages:
- Simple to implement
- Fast for accessing all the data in order
- Disadvantages:
- Not suitable for random access or updates in the middle of the file
- Direct Access (Random Access)
- In this, we can go directly to any part of the file without reading through the earlier parts.
- It is based on file blocks or record numbers.
- This accessing method is applied to
.mp4,.db,.pdftypes of files, i.e.,- Databases,
- Multimedia files (jumping to a time in a video),
- Indexing systems, etc.
- For example, jumping to page 50 in a PDF file without reading pages 1 to 49, or jumping to a specific song in an MP3 player
- It performs operations –
read(n)-Read from the nth block or location.write(n)seek(n): Move the pointer to a specific location.
- Advantages:
- Fast access to specific data
- Efficient for large files
- Disadvantages:
- Slightly more complex to manage
- The file structure must support random access
- Indexed Access
- An index is created that keeps track of where different parts of the file are stored.
- The OS uses the index to access data directly, but also indirectly through the index.
- This method is applied for Library catalogs, search systems, as in –
- Large databases
- Library systems
- Search systems
- For example, A book’s index helps us instantly find a chapter or topic, or use a table of contents in a book to find a topic.
- It performs operations –
read(index_location)write(index_location)search(key)
- Advantages:
- Fast access for both sequential and direct needs
- Efficient searching
- Disadvantages:
- Extra storage is required for the index
- Slower if the index becomes too large
- Sequential Access
Directory Structure
- Directory management is a crucial aspect of file management in operating systems.
- By organizing files and directories logically, enforcing permissions, and following best practices, users and administrators can ensure efficient and secure access to data.
- Modern operating systems provide robust tools and features to simplify directory management, making it easier to maintain order and optimize system performance. Whether through command-line interfaces or graphical user interfaces, effective directory management is essential for both personal and enterprise computing environments.
- Directory management is a fundamental aspect of file management in operating systems. Directory management refers to the set of OS services and data structures used to organize files into a logical, hierarchical structure and to perform operations on that structure. It involves organizing, storing, and retrieving files efficiently.
- A directory (also called a folder) is a container used to group files and other directories logically.
- Effective directory management ensures that users can easily locate, access, and manage files while maintaining system performance and security.
-
Key Terms of Directory Management
-
Directory Structure:
- Directories are organized hierarchically in most modern operating systems.
- The root directory is the topmost directory in the hierarchy.
- Subdirectories (or child directories) branch out from parent directories, forming a tree-like structure.
-
Path:
- A path specifies the location of a file or directory within the hierarchy.
- Absolute Path: Starts from the root directory to their existing location (e.g.,
/home/user/documents/file.txtin Linux). - Relative Path: Specifies the location relative to the current working directory (e.g.,
documents/file.txt).
- Absolute Path: Starts from the root directory to their existing location (e.g.,
- A path specifies the location of a file or directory within the hierarchy.
-
File System:
- The file system (e.g., NTFS, ext4, FAT32) defines how directories and files are stored and managed on storage devices.
-
Directory Operations:
-
Certain common operations include creating, renaming, moving, deleting, and listing directories.
-
-
-
Types of Directory Structures
There are the following categories of directories in an operating system:-- Single-Level Directory:
-
-
- This is the simplest directory structure.
- All files are stored in one big directory called root.
- It is very simple to implement.
- It is extremely limiting and now obsolete.
- It is inefficient for large numbers of files due to name conflicts and a lack of organization.
- It has a naming collision means that every file must have a unique name in a directory. We can’t have two files with the same name in the same directory.
- It becomes unmanageable as the number of files grows.
-
-
- Two-Level Directory:
-
-
- Here, each user has their own separate directory (user-specific directories), i.e., A Master File Directory (MFD) contains one User File Directory (UFD) for each user.
- This reduces/solves the naming collision problem or name conflicts between users, but still lacks flexibility for organizing files.
- Users cannot create subdirectories to organize their own files.
- Collaborating and sharing files between users is difficult and inefficient.
-

-
- Tree-Structured/Hierarchical Directory:
-
-
- This is the standard model used by virtually all modern operating systems (Windows, macOS, Linux).
- Here, files and directories are organized in a hierarchical tree structure.
- Here, a single root directory is at the top. Further, every directory can contain both files and other subdirectories.
- Extremely flexible, allows for deep and logical organization, and is intuitive for users.
- This structure supports subdirectories, allowing for better organization and improved scalability.
- Uses both Absolute and relative path concepts to locate their destination.
-
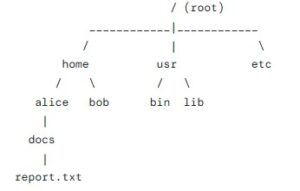
-
- Acyclic Graph Directory:
-
-
- This is an enhancement of the tree structure that allows for shared files and directories.
- A file or subdirectory can appear in multiple directories at the same time.
- This structure allows directories to share subdirectories or files using symbolic links.
- This structure enables shared access to files without duplicating them.
- Its implementation is achieved through links (or shortcuts in Windows). This link can be –
-
-
-
-
- Hard Link (Unix/Linux): A hard link is a direct pointer to the file’s data on the disk (its inode). Multiple directory entries point to the same physical file data. The file is only deleted when its last link is removed. Hard links cannot span across different disk partitions.
- Symbolic Link (Soft Link): A symbolic link is a special file that contains the path to another file or directory. It’s like a shortcut. If the original file is deleted, the symbolic link becomes a “broken” link. Symbolic links can span across partitions.
- This structure has no cycles because cycles can cause search algorithms to enter an infinite loop. This is why the structure is called acyclic (no cycles).
-
-
-
- General Graph Directory:
-
-
-
This structure allows more cycles in the directory structure (e.g., a directory referencing itself).
-
It requires additional mechanisms to prevent infinite loops during traversal.
-
-
-
Directory Operations
Modern operating systems provide tools and commands to manage directory operations effectively. Some common functions/operations are:
1. Creating New Directories- Using Command Examples:
- Linux/Unix:
mkdir <directory_name> - Windows Command Prompt:
mkdir <directory_name> - GUI: Right-click → New Folder.
- Linux/Unix:
2. Renaming Existing Directories- Using Command Examples:
- Linux/Unix:
mv old_name new_name - Windows Command Prompt:
rename old_name new_name
- Linux/Unix:
3. Deleting Existing Directories- Using Command Examples:
- Linux/Unix:
rmdir <directory_name>(for empty directories),rm -r <directory_name>(recursive deletion). - Windows Command Prompt:
rmdir /s <directory_name>
- Linux/Unix:
4. Moving Existing Directories- Using Command Examples:
- Linux/Unix:
mv source_path destination_path - Windows Command Prompt:
move source_path destination_path
- Linux/Unix:
5. Listing Directory Contents- Using Command Examples:
- Linux/Unix:
ls(list contents),ls -l(detailed view). - Windows Command Prompt:
dir
- Linux/Unix:
6. Changing the Current Directory- Using Command Examples:
- Linux/Unix:
cd <directory_path> - Windows Command Prompt:
cd <directory_path>
- Linux/Unix:
7. Creating Symbolic Links (Shortcuts)-
Using Command Examples:
-
Linux/Unix:
ln -s target_path link_name -
Windows Command Prompt:
mklink link_name target_path
-
- Using Command Examples:
-
Directory Permissions and Security
There are the following types of directory permissions usually seen in an operating system.-
Access Control:
- Operating systems enforce permissions to control who can read, write, or execute files and directories.
- Example:
- Linux/Unix:
chmod,chowncommands. - Windows: Right-click → Properties → Security tab.
- Linux/Unix:
-
Ownership:
- Each directory and file has an owner and group associated with it.
- Ownership determines who can modify permissions.
-
Encryption:
-
Sensitive directories can be encrypted to protect data from unauthorized access.
-
-
-
Advantages of the Directory Structure
-
Organize Logically:
-
To allow users to group related files into meaningful directories (e.g.,
Documents,Photos,Projects).
-
- Efficient Location:
- To quickly locate a file based on its name and path.
- Naming Convenience:
- To allow different files to have the same name, as long as they are in different directories.
-
Regular Cleanup:
- A directory helps in periodically deleting unused files and directories to free up space.
- Access Control:
- To control which users can access which files. Permissions are often managed at the directory level.
-
Automate Tasks:
- Use scripts or automation tools to handle repetitive tasks like backups or cleanup.
-
Monitor Disk Usage:
-
Keep track of disk space usage to avoid running out of storage.
-
-
- Directory Implementation on Disk
Internally, the OS implements a directory structure to store the contents on the hard disk in two forms mainly –
-
- Linear List Form: A simple list of file names and pointers to their data blocks.
- Pros: Simple to implement.
- Cons: Very slow for searching.
- Hash Table Form: A more advanced structure that uses a hash function on the file name to find its entry in the directory.
- Pros: Extremely fast for lookups.
- Cons: More complex to implement, and must handle collisions (when two different file names hash to the same value).
- Linear List Form: A simple list of file names and pointers to their data blocks.
File Operations Activities
- The OS provides various operations for managing files, such as creating, opening, closing, reading, writing, deleting, copying, moving, and renaming files etc. These operations are typically performed through system calls or higher-level file management APIs.
- The file system is the underlying structure in an operating system that manages how files are stored, named, and accessed on a storage device (such as a hard drive or SSD). Some common file systems of operating systems are NTFS (Windows), HFS+ (Mac), and ext4 (Linux).
- There are specific file management features and tools available for operating systems that may vary depending on the operating system we’re using. But some common file operations are usually seen in file management activities by an OS, which are given as follows:-
-
-
File Operations:
-
Creating Files: Users can create new files and specify their names, types, and locations. Applications can also create files to store data.
-
Deleting Files: Files can be permanently removed from the file system.
-
Copying Files: Files can be duplicated, creating a new copy in a specified location.
-
Moving Files: Files can be relocated within the file system, including moving them between directories or storage devices.
- Modifying Files: The content of files can be modified as needed.
-
Renaming Files: File names can be changed without modifying the file’s contents.
-
-
File Access, Permissions, and Security:
-
The OS enforces access control mechanisms to protect files from unauthorized access. Permissions, such as read, write, and execute, can be assigned to users or groups, specifying who can perform specific operations on a file.
- File permissions determine who can read, write, and execute files, and they can be set for individual users or groups.
- File management includes controlling access to files and ensuring data security.
-
-
File Metadata:
-
Along with file attributes, file systems can store additional metadata about files, such as file ownership, access control lists (ACLs), extended file attributes (e.g., file tags or comments), and file indexing information (e.g., for fast searching).
-
-
File Searching & Retrieval:
-
OSes often provide mechanisms to search for files based on various criteria, such as file names, file types, or specific content within files. This allows users to quickly locate files on their systems.
-
Search capabilities may be integrated into the file explorer or provided through dedicated search tools.
-
-
File Compression and Encryption:
-
OSes may support file compression to reduce storage space and file encryption to protect sensitive data. Compressed files are typically smaller and need to be decompressed before use, while encrypted files require decryption using an appropriate key or password.
- Common file compression formats include ZIP, RAR, and GZIP.
-
-
File Backup and Recovery:
-
Backup and recovery mechanisms enable users to create copies of important files or the entire file system to protect against data loss.
-
OSes may provide built-in backup utilities or rely on third-party software for this purpose.
- Regular backups create copies of files that can be restored in case of accidental deletion, hardware failures, or other issues.
-
-
File System Maintenance:
-
OSes often include tools to perform routine file system maintenance tasks, such as disk defragmentation (reorganizing fragmented files for improved performance) and disk error checking and repair.
-
- File Sharing:
- Some operating systems support file sharing, allowing users on the same network to access files stored on remote computers. This facilitates collaboration and file exchange between users.
-
File Allocation Methods
- A storage device (like an SSD or HDD) is organized into fixed-size blocks. When a file needs to be saved, the operating system must decide which of these blocks to allocate to the file.
- File allocation methods are the strategies that an operating system uses to assign disk blocks to files.
- In other words, File allocation methods refer to the techniques used to allocate disk space for files.
- These allocation methods determine how and where data is stored on a storage device (e.g., hard disk or SSD).
- The choice of allocation method depends on the specific requirements of the operating system and the workload it supports. In other words, the choice of file allocation method directly impacts disk space efficiency, file access speed, and the ability of files to grow over time.
- Modern file systems often use indexed allocation or a hybrid approach to balance performance, flexibility, and storage efficiency. Understanding these methods helps in designing efficient file systems and optimizing storage management in operating systems.
Types of File Allocation Methods
There are three primary methods of file allocation:
- Contiguous/Continuous Allocation
- Non-Continuous Allocation
- Linked/Chained Allocation
- Indexed Allocation
- Combined/Hybrid Allocation
1. Contiguous Allocation
- This is the simplest allocation method.
- It requires that each file occupy a single, continuous set of blocks on the disk.
How it Works:
- When a new file is created, the OS looks for a contiguous chunk of free blocks large enough to hold the entire file.
- The directory entry for the file stores only two pieces of information: the starting block address and the length of the file (in blocks).
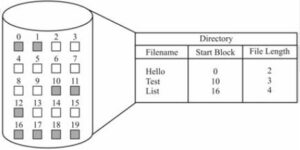
Advantages
- Fast Access:
- Sequential and direct access are efficient in this because all blocks are stored together.
- Simple Implementation:
- Easy to implement and manage.
Disadvantages
- External Fragmentation:
- Over time, free space becomes fragmented, making it difficult to find large contiguous blocks for new files.
- File Growth Issues:
- If a file exceeds its allocated space, it may require moving the entire file to a new location with sufficient contiguous space.
- Wastage of Space:
- Pre-allocating space for files can lead to unused reserved space.
Use Case
- Suitable for systems with small, static files (e.g., embedded systems).
2. Linked Allocation
- Files are stored as a linked list of disk blocks.
- Each block contains a pointer to the next block in the file.
- This method solves the fragmentation problems of contiguous allocation by storing a file as a linked list of disk blocks, which can be scattered anywhere on the disk.
How it Works:
- The directory entry for a file contains a pointer to the first block of the file.
- The first block of a file contains data and a pointer to the next or second block.
- The second block points to the third block, and so on. Thus, each block contains not only the file’s data but also a pointer to the next block in the chain.
- The last block has a null pointer indicating the end of the file.
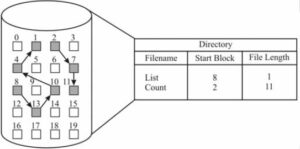
Advantages
- No External Fragmentation:
- Blocks can be scattered across the disk, eliminating the need for contiguous space.
- Dynamic File Growth:
- Files can grow dynamically without needing to move existing data.
Disadvantages
- Slow Random Access:
- To access the nth block, the OS must traverse the linked list from the beginning, which is inefficient.
- Pointer Overhead:
- Each block requires additional space to store the pointer to the next block.
- Reliability Issues:
- Corruption of a pointer can make the rest of the file inaccessible.
Use Case
-
Suitable for sequential access workloads (e.g., log files).
3. Indexed Allocation
- An index block stores pointers to all the data blocks of a file.
- The index block acts as a table of contents for the file.
- In other words, this method brings all the pointers for a file together into one location: an index block.
- It solves the direct access problem of linked allocation.
How it Works:
- For each file, there is a dedicated index block.
- The directory entry for the file contains a pointer to this index block.
- The index block is an array of pointers, where the i-th entry in the index block points to the i-th data block of the file.
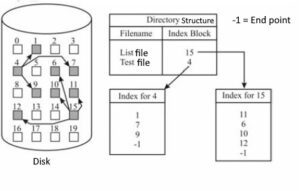
Advantages
- Efficient Random Access:
- Any block can be accessed directly using the index block.
- No External Fragmentation:
- Blocks can be scattered across the disk.
- Dynamic File Growth:
- New blocks can be added easily by updating the index block.
Disadvantages
- Index Block Overhead:
- Requires additional space for the index block.
- Limited File Size:
- The size of the index block limits the maximum number of blocks a file can have.
- Complexity:
- Managing index blocks adds complexity to the file system.
Types of Indexed Allocation
- Single-Level Indexing: One index block per file.
- Multi-Level Indexing: A “master” index block points to second-level index blocks, which in turn point to the data blocks. Uses multiple levels of index blocks to support larger files (e.g., Unix inode structure).
Use Case
-
Commonly used in modern file systems like ext4 and NTFS.
4. Combined Allocation (Linked + Indexed)
Overview
- Combines the benefits of linked and indexed allocation methods.
- Some file systems use a hybrid approach to optimize performance.
Example
- Unix OS Inode Structure:
- Direct blocks: Pointers to the first few blocks of the file.
- Indirect blocks: Pointers to blocks containing more pointers (single, double, or triple indirect blocks).
Advantages
- Balanced Performance:
- Combines the efficiency of indexed allocation with the flexibility of linked allocation.
- Supports Large Files:
- Multi-level indexing allows for very large files.
Disadvantages
- Increased Complexity:
- More complex to implement and manage.
Use Case
-
Used in advanced file systems like ext4 and XFS.
Free Space Management
Introduction
- This is a core function of an operating system’s file system management.
- Free space management is a critical aspect of file system design in operating systems.
- It involves tracking and managing unused free blocks on a storage device (e.g., hard disk, SSD) to ensure efficient allocation of space for new files and directories.
- This is essentially the OS’s “inventory system” for available storage space.
- The efficiency of this system is critical because it directly impacts the performance of file creation, writing, and deletion.
Definition
- Free space management is the task of keeping track of all the disk blocks that are not currently allocated to any file or directory.
Objectives
- This management is helpful in finding/providing free space quickly.
- This technique utilizes disk space as effectively as possible with minimal overhead.
- The free space management technique should work well with the different types of file allocation methods being used (contiguous, linked, or indexed).
- Proper free space management minimizes fragmentation, maximizes storage utilization, and ensures fast file operations.
- The purpose of free space management is to keep track of unallocated blocks on the disk so that they can be assigned to new files or directories.
- Free space management techniques aim to minimize fragmentation.
Characteristics
- When a new file needs to be created or an existing file needs to grow, the OS consults its free space management system to find and allocate the necessary blocks.
- When a file is deleted, its blocks are returned to the free space pool so they can be reused.
- Different file systems implement free space management differently. For example –
-
ext2/ext3/ext4 (Linux File Systems):
-
Use the bitmap method to track free blocks and inodes.
-
The superblock contains information about the location of the block and inode bitmaps.
-
-
NTFS (Windows File System):
-
Uses a bitmap to track free clusters (groups of blocks).
-
Also employs advanced features like compression and sparse files to optimize space usage.
-
-
FAT (File Allocation Table):
-
Uses a linked list-like structure in the FAT to track free clusters.
-
Each entry in the FAT indicates whether a cluster is free or allocated.
-
-
Btrfs/ZFS:
-
Use advanced techniques like copy-on-write and snapshots to manage free space dynamically.
-
ZFS uses a pool of free blocks and dynamically allocates space as needed.
-
-
Free Space Management Methods
-
Operating systems use various techniques/methods to manage free space. These are –
1. Bit Vector (Bitmap) Method
-
How It Works:
- A bitmap is a sequence of bits where each bit represents a block on the disk.
- 0 indicates the block is free, and 1 indicates the block is allocated.
- For example, if a disk has 8 blocks and blocks 2, 3, and 6 are allocated, the bitmap would look like: 00110010
-
Advantages:
- Simple and compact representation.
- Fast for checking the status of a block.
- Efficient for contiguous allocation since it allows quick identification of large free spaces.
-
Disadvantages:
- Bitmap size grows with the number of blocks, which can be significant for large disks.
- Finding the first free block requires scanning the bitmap sequentially unless optimized.
-
Use Case:
-
Commonly used in modern file systems like ext2/ext3/ext4.
-
2. Linked List (Free List) Method
-
How It Works:
- Free blocks are linked together in a list, where each free block contains a pointer to the next free block.
- The OS maintains a pointer to the first free block.
-
Advantages:
- No additional space is required for metadata (pointers are stored in the free blocks themselves).
- Efficient for linked allocation methods.
-
Disadvantages:
- Slow access to free blocks since the list must be traversed sequentially.
- Overhead of maintaining the linked list (e.g., updating pointers when blocks are allocated or freed).
-
Use Case:
-
Suitable for systems with simple file allocation methods like linked allocation.
-
3. Grouping Method
-
How It Works:
- Similar to the linked list method, but instead of linking individual blocks, groups of blocks are linked.
- Each group contains a list of pointers to other free blocks.
- The first block in a group stores pointers to other free blocks, reducing traversal time.
-
Advantages:
- Faster than the simple linked list method because multiple free blocks can be identified at once.
- Reduces the overhead of pointer management.
-
Disadvantages:
- Still slower than the bitmap method for identifying free blocks.
-
Use Case:
-
Useful for systems where free space is fragmented, but grouping can improve efficiency.
-
4. Counting Method
-
How It Works:
- Instead of tracking individual blocks, the system tracks ranges of contiguous free blocks.
- Each entry in the free space list contains:
- The starting address of a range of free blocks.
- The count of contiguous free blocks in that range.
-
Advantages:
- Compact representation for large contiguous free spaces.
- Efficient for contiguous allocation.
-
Disadvantages:
- Fragmentation can lead to many small ranges, increasing the size of the free space list.
- Complex to implement and maintain.
-
Use Case:
-
Suitable for systems with contiguous allocation or large free spaces.
-
Disk Scheduling
![]()
0 Comments